
В конце прошлой недели Владимир Путин впервые провел открытое совещание по теме развития искусственного интеллекта в России. «Если кто-то сможет обеспечить монополию в сфере искусственного интеллекта — тот станет властелином мира», — резюмировал президент и предложил активное содействие во всем, что связано с ИИ, в том числе содействие инвестиционное: на развитие отрасли планируется потратить около 90 млрд рублей в ближайшие шесть лет.
Чтобы государственная инициатива не кончилась провалом, разбираемся в трудностях развития искусственного интеллекта и в том, как эти трудности преодолеть.
Коммунизма призрак по Европе рыскал,
уходил и вновь маячил в отдалении…
(В.В. Маяковский)
Если в приведенном эпиграфе слово «Коммунизм» заменить на «искусственный интеллект» (ИИ), а «Европу» на «Мир», его смысл окажется более чем современным. Действительно, технологии, основанные на использовании возможностей нейронных сетей, стремительно внедряются практически во все области человеческой деятельности. Не стала исключением и медицина.
Реальная польза или эйфория от модного термина?
Совершенно очевидно, что искусственный интеллект не отделим от компьютерных информационных технологий. Другими словами, только в тех областях можно рассчитывать на успех, где активно используются и наполняются качественными записями хранилища данных. С другой стороны, раз возможности и производительность вычислительной техники год от года возрастают, то видимо и в части технологий «Big Data», лежащих в основе ИИ, «все пути для нас открыты, все дороги нам видны…». Отсюда вытекает логичный на первый взгляд вывод — возможности искусственного интеллекта безграничны и заоблачные высоты без особого труда достижимы. На этом фоне совершенно не хочется задумываться о существовании возможных ограничений. И напрасно.
Положение дел очень напоминает ситуацию периода 2008 – 2012 гг., когда среди медицинского сообщества стало распространяться представление о «неограниченных возможностях информатизации». Некоторым руководителям казалось даже, что внедрение МИС разом закроет все проблемы МО. Чтобы эйфория прошла и медицинские информационные системы заняли в работе организаций предназначенное им место, потребовался опыт нескольких лет их активной эксплуатации.
Возможности МИС оказались несколько скромнее максимальных ожиданий руководителей МО, но зато и перспективы повышения эффективности их использования значительно выходят за пределы первоначально поставленных перед ними задач. В результате неизбежность комплексной информатизации здравоохранения стала для всех очевидной. Точно также и использование в недалеком будущем систем экспертной поддержки решений, основанных на возможностях ИИ, весьма вероятно.
Надо, однако, понимать, что использование «искусственного интеллекта» в медицине не относится к задачам сегодняшнего дня. Причин этому много. Не на последнем месте стоит, в частности, недостаточное правовое обеспечение соответствующих проектов. Не стоит в этих вопросах и от Министерства ждать милости. Надо, безусловно, «бороться и искать, найти и не сдаваться!». Но не следует и воздушные замки строить. И уж тем более считать, что «искусственный интеллект» уже готов к внедрению в практическую медицину. Кое-что «нейронные сети» могут конечно уже и сегодня. Надо лишь определить, в каких направлениях и с какой степенью надежности на их «рекомендации» можно полагаться в области задач здравоохранения.
Типичным подтверждением сказанному являются результаты конференции по искусственному интеллекту в медицине, которая проходила в Салехарде 5 апреля 2019 года. Участникам, в частности, сообщили, что по результатам опытного внедрения искусственного интеллекта в больнице Муравленко выявление факторов риска онкозаболеваний увеличилось в семь раз, а из тридцати тысяч обработанных электронных медицинских карт пациентов, прикрепленных к лечебному учреждению, в одной трети из них были обнаружены предпосылки к возникновению заболеваний сердца.
Результат удивительный, но порождает смутные сомнения. Из итоговых публикаций сложно, к сожалению, однозначно интерпретировать логику работы ИИ в конкретной организации (больница Муравленко). С одной стороны, проводилось обучение экспертной системы, при котором «были использованы данные городской больницы – более 1,3 млн документов». Этот подход, кстати, полностью соответствует классической идеологии машинного обучения. С другой стороны, «Система подсчитывает риск сразу по четырем методикам». Хотелось бы в этом случае понять:
- Использовалась ли экспертная система, в основе которой лежала реальная математическая модель, полученная в результате настройки нейронной сети на основе данных электронных медицинских карт 25-ти тысяч пациентов? Или
- Система была настроена на обработку данных ЭМК (анализы, обследования, жалобы…) по известным ранее методикам определения риска заболевания? Или
- Использовались четыре независимые математические модели, построенные путем машинного обучения на различных по составу и структуре массивах данных?
Согласитесь, что уровни доверия к прогнозу для каждого из этих подходов будут различными.
Несколько настораживает и то обстоятельство, что из дополнительно обследованных шестисот пациентов, для которых ИИ определил высокий риск кардиологических заболеваний, на диспансерный учет были поставлены 67! То, что на этих пациентов обратили внимание, безусловно, замечательно, но 89% вероятных «ложноположительных» ответов — это несколько выше уровня, ожидаемого для качественно настроенной нейронной сети. И можно ли в этом случае дать гарантию, что экспертная система не выдала сопоставимое количество и «ложноотрицательных» прогнозов?
Это, конечно, конспирология, но объяснения по приведенному выше результату могут лежать и в совершенно иной плоскости. Причиной может стать недостаточная точность (адекватность) используемой математической модели в сочетании с взаимной заинтересованностью как разработчиков, так и пользователей ИИ именно в таком результате. К разработчику при этом не предъявляется жестких требований по качеству подготовки данных, необходимых для машинного обучения (для настройки нейронной сети), а лечебное учреждение получает подтверждение необходимости увеличения своего бюджета в связи с обязательностью проведения множества дополнительных обследований.
Часть приведенных выше высказываний, скорее всего, «мелкие придирки и инсинуации». Однако эйфория от первых успехов может реально вскружить голову и привести к неожиданным и далеко не всегда приятным последствиям. Всеми силами хотелось бы этого избежать, тем более что перспективы искусственного интеллекта, если ставить перед ним задачи, под которые он реально заточен, действительно вдохновляют. Для тех, кто в силу своей занятости в тему пока еще недостаточно глубоко погрузился, мы попробуем приподнять завесу таинственности над сутью процессов, формирующих ядро ИИ.
Некоторые особенности нейронных сетей и подходов к их настройке
«Искусственный интеллект» — это инструмент, основанный на математической модели процесса принятия решения, которая, в свою очередь, основана на выявленных ранее зависимостях и закономерностях. В качестве ядра ИИ может, в частности, использоваться и в явном виде записанное уравнение регрессии. В этом случае мы можем напрямую оценивать как влияние на значение функции цели каждого из рассматриваемых факторов, так и общую погрешность результата.
Современные подходы, использующие настройки нейронных сетей, отличаются (от подходов, использующих статистические методы получения регрессионных уравнений) в основном привлечением к разработке математической модели алгоритмов, которые на выходе формируют «вещь в себе». Проверка адекватности такой модели на этапе ее создания проводится путем сверки «предсказаний» ИИ с заранее известными целевыми значениями подготовленных тестовых записей. Предполагается, что в процессе эксплуатации экспертная система должна постоянно развиваться и повышать точность прогноза путем донастройки своего ядра, используя для этого вновь формируемые записи.
До настоящего времени в коммерческом сегменте присутствовали в основном так называемые «заблокированные алгоритмы ИИ». Разработанные на их основе экспертные системы существуют в виде самостоятельных программных модулей, воспринимаемых пользователями как «черный ящик». Как правило, они размещаются в «облаке» и поддерживаются разработчиками. Суть использования ресурса заключается в передаче на вход ИИ описаний конкретных процессов с откликом системы в виде «вероятного результата», или «оптимальной (с точки зрения ИИ) рекомендации». Состав таких описаний и алгоритм передачи согласуются с разработчиком (владельцем ресурса), и повышение качества прогноза используемых для этого нейронных сетей доступно также только ему.
Здесь мы сталкиваемся с первыми проблемами. Поставим себя на место специалиста, не имеющего доступа к информации по «knowhow» разработчика экспертной системы. Мы вынуждены или полностью доверять выводам (рекомендациям) ИИ, или от них отказаться. Предпочтение, естественно, отдается первому варианту. При этом мы не знаем на каких и по каким методикам подготовленных массивах данных проводилось обучение конкретной реализации нейронной сети. Это может быть как неструктурированный текст определенного раздела электронной истории болезни, так и структурированный набор данных. Не исключено, что при обучении использовались и фрагменты изображений или антропометрические показатели.
Нетрудно понять, что любые информационные массивы, используемые для обучения нейронных сетей, несут на себе отпечатки личности специалистов, их формирующих. Формулировки, термины, обозначения, выводы всегда будут, пусть и незначительно, отличаться. Исключением могут являться только записи, создаваемые на основе использования согласованных словарей, структурированных справочников, или данных объективных исследований. Но и этом случае на качество прогноза может существенно повлиять, например, марка анализатора, или качество реагента, если эти факторы при формировании модели не учитывались. Иными словами, прежде чем внедрять в свою практику искусственный интеллект, полезно как минимум познакомиться с перечнем показателей, использовавшихся при обучении системы, а также с общим объемом выборки данных. Понятно, что в случае закрытости информации по «knowhow» сделать это проблематично.
Предпочтительнее в этом смысле настраивать нейронные сети на данных, самостоятельно сформированных конкретной медицинской организацией. Этот процесс становится аналогом своеобразного консультирования менее опытных врачей старшими товарищами, работающими по тем же методикам и технологиям. Если при этом ИИ встраивается в структуру (становится элементом) рабочего варианта эксплуатируемой МИС, в значительной степени упрощается и проблема динамического повышения качества предсказаний и рекомендаций. Наконец, даже значительное изменение методик предоставления услуг, номенклатуры лекарственных препаратов, приборного оснащения и т.д., легко учитывается в модели путем ее повторного обучения на расширенном составе данных. В то же время качество рекомендаций «внешнего ИИ» в аналогичной ситуации может существенно снизиться.
В заключение раздела хочется обратить внимание на высокую вероятность возникновения различий в подходах к созданию и эксплуатации ИИ, ориентированных на решение аналогичных задач. Прежде всего, методы (алгоритмы) настройки нейронных сетей не являются секретом. Они общедоступны и при желании могут использоваться любым специалистом или любой организацией самостоятельно. Все тонкости и отличия связаны с постановками задач, с подготовкой массивов данных для машинного обучения и с методиками последующего повышения качества полученных математических моделей. В результате различными становятся времена подготовки и тестирования экспертных систем, их адаптивность к конкретным технологиям лечения, принципиальная возможность повышения точности «предсказаний» и доступность модернизации.
Направления эффективного использования ИИ
Наибольшее распространение технологии «искусственного интеллекта» получили в области кластерного анализа. Сюда относятся, в частности, задачи распознавания образов (текст, речь, фотографии…), диагностики и т.п. То есть, системе (ИИ) предлагается на основе реквизитов, описывающих объект, отнести его к той или иной группе. Причем указанные группы могут содержать как множество элементов (множество кошек, множество собак, признаки заболевания и пр.), так и единичные экземпляры (например, фотографии конкретных пациентов).
Интуитивно понятно, что, пропустив фотографию пациента через нейронную сеть, настроенную на задачу разделения «кошек» от «собак», ответ мы конечно получим. ИИ не может «зависать». Он всегда возвращает значение вероятности соответствия изображения определенному классу объектов. Но это, видимо, будет не совсем тот результат, на который мы рассчитываем. Другими словами, если нас интересует корректный прогноз, мы, как минимум, должны быть уверены, что:
- Используемая нами нейронная сеть (ИИ) настроена именно на ту задачу и прогноз того результата, которые нас интересуют.
- Запись, которую мы подаем на «вход» модуля ИИ, по своему составу и значениям терминов в значительной степени совпадает с подбором данных, на которых проводилось машинное обучение (настройка нейронной сети).
- Можно полагаться на опыт, компетентность и ответственность специалистов, записи которых использовались для формирования обучающей выборки.
- Структура (текст) электронных карт, на основе записей которых проводилась настройка и тренировка ИИ, действительно соответствуют логике внесения информации в МИС пользователя.
В перечень перспективного поиска направлений эффективного использования ИИ можно, видимо, включить и:
- Оптимизацию состава и последовательности диагностических мероприятий с учетом предварительно полученных результатов.
- Варианты оптимизации лечебных мероприятий, исходя из текущего состояния пациента, установленного диагноза и доступных ресурсов.
- Прогноз результата стационарного лечения с учетом начальных условий и возможной последовательности вариантов воздействий на пациента при выборе того или иного лечебного стандарта.
- Выбор оптимального состава и последовательности оперативных лечебных мероприятий с учетом динамики изменения состояния пациента, и т.д.
Эти задачи существенно сложнее. Соответственно и возможность практического использования ИИ с целью их эффективного решения пока не очевидна. Тем не менее, все развивается. Если разумно выстроить последовательность согласованных шагов поиска и исследований, успех вполне вероятен.
Не менее перспективными могут оказаться и направления использования ИИ, связанные повышением эффективности контроля качества предоставления медицинских услуг. Отталкиваясь от «стандарта» лечебного процесса, можно настраивать нейронные сети на прогнозирование длительностей лечения, учитывающих:
v основной и сопутствующий диагнозы;
v историю заболевания;
v структуру предоставленных услуг;
v результаты промежуточных обследований;
v возникающие осложнения и пр.
При этом случаи лечения, длительность которых существенно отличается от прогноза, формируемого ИИ, с большой долей вероятности могут содержать «ошибочно» внесенную в систему информацию или значимые пропуски в структуре описаний.
Для наглядности в конце публикации приводится пример вариантов настроек несложной нейронной сети и сравнение полученных при этом результатов.
Подводные камни ИИ.
Немного подробнее остановимся на вопросе закрытости процессов подготовки ИИ, используемого для определения на ранних стадиях вероятности онкозаболеваний. Для предварительной оценки адекватности прогноза было бы полезно знать:
- На каких объемах выборки изображений проводилось обучение ИИ и какая аппаратура для получения изображений использовалась?
- Использовались для обучения только рентгеновские снимки, компьютерная томография и подобные изображения, или совместно с ними рассматривались выводы (заключения) специалистов, неструктурированный текст, совокупность значений конкретных понятий и т.д.?
- Какую часть обучающей выборки составляли снимки, относящиеся к гарантированно здоровым пациентам?
- Какую часть выборки составляли снимки, связанные с гарантированной фиксацией онкозаболеваний на ранней стадии?
- Какое значение «MSE» (среднеквадратичная ошибка) демонстрировала модель ИИ на тестовых выборках?
- Немаловажной для задач кластеризации является и информация о процентных значениях ложноположительных и ложноотрицательных прогнозов, полученных при тестировании настроенной нейронной сети.
Если соответствующие сведения доступны, можно по крайней мере оценить вероятную погрешность «предсказания» и сопоставить возможности аппаратуры, на основе которой формировалось обучающее множество изображений, с качеством снимков и соответствующих им записей, имеющихся в распоряжении конкретного медицинского учреждения.
Как уже описывалось выше, ИИ совсем не обязательно должен помещаться в «облако». В виде альтернативного может рассматриваться подход, в рамках которого настройка нейронной сети проводится на основе изображений и записей, накопленных самой медицинской организацией. Модули, использующие ИИ, можно было бы интегрировать с функционалом конкретной МИС МО. Аргументация нецелесообразности такого подхода, связанная с якобы прямой зависимостью точности предсказаний экспертных систем от объемов записей в обучающих выборках, далеко не всегда подтверждается практикой. Объединение данных, порождаемых различными методиками лечения (диагностики), скорее вносят дополнительный «информационный шум» в процесс обучения, чем повышают его эффективность.
Кроме того, настройка нейронной сети, лежащей в основе искусственного интеллекта, ничем невероятно сложным не является. Процесс, по существу, связан с определением «веса» (коэффициента) каждого из рассматриваемых факторов (параметров, реквизитов…) обучающей выборки с точки зрения его вклада в значение целевого показателя. Процесс «прогнозирования» в примитивной интерпретации сводится, таким образом, к расчету вероятного значения функции цели путем «перемножения» соответствующих «весовых показателей» модели на значения реквизитов, описывающих реальный объект (процесс) с учетом возможных отклонений. Единственным, пожалуй, существенным отличием нейронной сети от уравнений линейной регрессии является отказ от представлений о наличии априори нормального распределения значений рассматриваемых факторов влияния. Кроме того, алгоритмы «Big Data» дают возможность включения в описание модели не только числовых данных, но и фрагментов текста («количественные» и «номинальные» факторы соответственно).
Вывод о принадлежности рассматриваемого объекта или процесса к той или иной группе (к тому или иному кластеру, к тому или иному целевому показателю) оценивается по значениям реквизитов его описания. Естественно, что качество прогноза (кроме, конечно, результатов настройки нейронной сети) напрямую зависит от степени совпадения составов реквизитов описания объекта со структурой обучающей выборки. Если понятие (фактор) анализируемой записи в обучающей выборке отсутствует, его значение искусственным интеллектом или игнорируется, или воспринимается в виде «шума». Еще большую погрешность в прогнозы вносит отсутствие в запросе значений понятий, использовавшихся при обучении. Последнее, правда, справедливо при «большом весе» указанного понятия в настройках нейронной сети.
Считается, что качество результата, получаемого с помощью ИИ, определяется числом циклических итераций при его подготовке. Они состоят из:
- Выявления максимально достоверных записей, связывающих их реквизиты с надежными значениями «функции цели». Представление, что алгоритм настройки сам отсеивает весь «информационный мусор» и незначимые факторы, далеко не всегда оправдывается. Зачастую избыток данных при обучении не менее вреден, чем их недостаток.
- Исключения из обучающей выборки (по меньшей мере при использовании ИИ для количественного прогнозирования) корреляционных зависимостей между факторами.
- Определения «весовых характеристик» учитываемых факторов и их сочетаний (настройка нейронной сети).
- Оценок (на тестовых выборках) качества «предсказания» и попыток определения возможных причин ошибок в ситуациях, когда принадлежность случая к конкретному кластеру (к конкретному значению «функции цели») очевидна, а прогноз отрицателен.
Многие разработчики декларируют целесообразность использования подходов к обучению, основанных на обработке всей совокупности данных по объектам (процессам), описания которых хранятся в базах данных МИС. При этом значительная часть таких описаний может представлять собой неструктурированный текст. Обнадеживающие результаты на этом пути демонстрируют пока только процессы «угадывания пристрастий» пользователей социальных сетей. На этом основании рекламодателей можно, вероятно, поздравить. Но согласитесь, что реклама и диагностика различаются не только своими задачами, но и ответственностью за результат. Дополнительно настораживает и то, что, по мнению некоторых банкиров, падение эффективности кредитования в ряде случаев может объясняться именно излишне активным внедрением технологий ИИ в процедуры одобрения кредитов.
В каком направлении двигаться, или «вместо заключения»
Никто не оспаривает утверждения, что технологии ИИ могут эффективно работать. Поэтому важно, и именно на первом этапе, определить наиболее перспективные направления их использования и последовательность необходимых для этого шагов. Как уже упоминалось, приемлемые результаты демонстрируют пока только возможности искусственного интеллекта в части анализа изображений. Но это совсем не означает, что всем имеет смысл сосредотачиваться именно на этой проблематике. Желающих и уже накопивших определенный опыт работы в этом направлении вполне достаточно. Гораздо полезнее было бы обсудить и согласовать подходы к анализу возможностей нейронных сетей, связанных с диагностикой, с оценками рисков и с прогнозированием исходов заболеваний.
Рациональной, как нам кажется, могла бы стать следующая последовательность шагов:
- Выбор несколько крупных федеральных или региональных медицинских центров, имеющих многолетний опыт эксплуатации современных компьютерных информационных систем.
- Согласование совпадающих по целевым функциям задач, решение которых возможно на основе привлечения технологий ИИ, при договоренности об использовании центрами различных подходов к настройке нейронных сетей (различные разделы электронных медицинских карт, структурированный или неструктурированный текст, данные объективных исследований или заключения, сделанные на их основе специалистами и т.д.).
- Подготовка моделей (ядер) для ИИ и оценка прогностических возможностей соответствующих экспертных систем при работе с пациентами МО, ресурсы МИС которых использовались для формирования обучающих выборок.
- Реализация попытки «обмена моделями» (или исходными массивами данных для обучения ИИ) между центрами. Результатом должно стать сопоставление прогностических возможностей ИИ на основе использования альтернативных обучающих выборок в качестве тестовых (проверочных). В случае удовлетворительного результата — проверка возможности настройки нейронной сети на объединенных наборах записей. В случае неудачи — анализ эффективности сравниваемых моделей и выбор наиболее рационального варианта базового обучения системы.
При скоординированных действиях реализация подобного проекта вполне могла бы уложиться в 6 месяцев. При этом могли бы быть получены ответы на весьма важные вопросы:
- Какова прогностическая возможность специализированных экспертных систем, обученных на различных по структуре и составу массивах данных?
- Какова прогностическая возможность экспертных систем, обученных на массивах данных, полученных из внешних МИС?
- Повышается ли прогностическая возможность экспертных систем при их обучении на выборках данных, объединяющих массивы с различными наборами понятий (реквизитов)?
- Имеет ли смысл стандартизация структуры данных и соответствующих словарей МИС с целью формирования обучающих выборок для настройки нейронных сетей, пригодных для эффективного использования в экспертных системах различных медицинских организаций?
Пример для наглядности
В качестве примера использования искусственного интеллекта в медицинской организации рассмотрим простенькую задачу, связанную с прогнозированием продолжительности лечебного процесса. Для настройки необходимой нам модели (ядра ИИ) использовался алгоритм DeepLearning. Соответствующая обучающая выборка состояла из 3000 записей и включала в себя значения следующих показателей:
- Временной интервал (дни) от момента поступления пациента в стационар до его окончательной выписки (функция цели).
- Возраст и пол пациента.
- Отделение выписки из стационара.
- Диагноз выписки.
- Количество переводов между отделениями в процессе лечения.
- Вид операционного вмешательства и длительность его ожидания.
- Наличие и количество осложнений.
Первый (упрощенный) вариант реализации алгоритма привел к формированию модели, «MSE» которой определялось значением 34,53. Усложнение настроек (характеристик) алгоритма привело к снижению этого показателя до значения 28,89. Результат нас не удовлетворил. Поэтому следующий цикл обучения мы провели, введя в состав обучающей выборки данных два дополнительных параметра:
- Наличие сопутствующего заболевания.
- Факт отличия первоначально установленного (предварительного) диагноза, или диагноза поступления от диагноза выписки.
Построенная на этих данных модель продемонстрировала существенно лучший результат («MSE»=10,67). Усложнив настройки нейронной сети (существенное увеличение «скрытых слоев», увеличение числа «эпох» и т.д.), мы столкнулись с увеличением времени настройки модели в 5 раз при повышении качества прогноза на 12% («MSE»=9,4). В данном случае затраты на улучшение модели себя, видимо, не оправдывают. Гораздо эффективнее было бы в данном случае заняться поиском дополнительных факторов, влияющих на результат.
На рисунке 1 приведены фрагменты прогнозов, связанных с записями по лечебным процессам, которые были подготовлены самостоятельно и никак не связаны с данными, использованными для настройки нейронной сети и с процессом обучения как таковым. «Первый – второй» и «Третий – четвертый» столбцы сопоставления относятся к результатам прогнозирования на основе первой и второй модели.
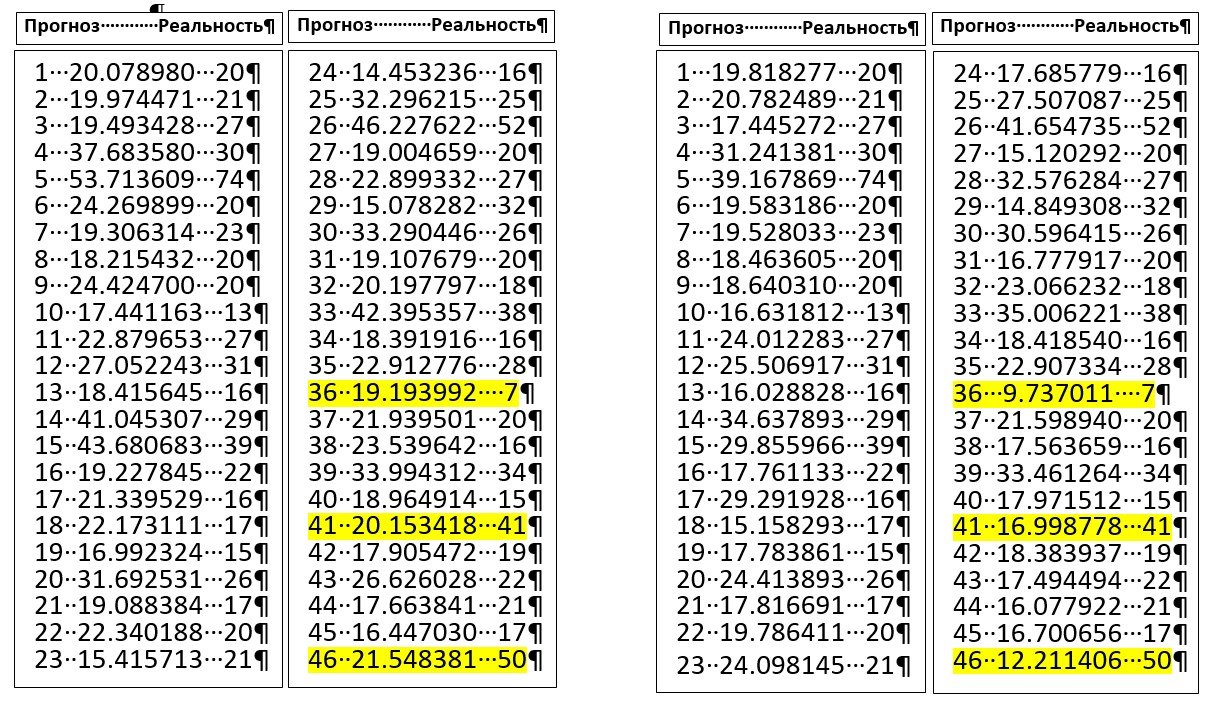
Рис. 1
Рисунок 1. Соответствие «прогноза ИИ» (длительность лечебного процесса), полученного на основе использования разных моделей, реальным данным, полученным из описаний независимых лечебных процессов.
Первое, что бросается в глаза:
- Число «улучшений» и «ухудшений» прогнозов, полученных при использовании уточненной модели, по отношению к первому результату настройки ИИ примерно одинаковы. То есть, улучшение «MSE» модели на 12% принципиальных изменений в итоговый результат не вносит.
- Прогноз по корректным записям (процесс № 36): уточненная модель улучшается, а «выбросы» становятся еще более очевидными (процессы №№ 41 и 46). Это может явиться достаточным основанием для анализа соответствующих записей заинтересованными лицами.
- Модели устойчивы. Повторный прогноз независимых описаний полученные ранее результаты сохраняет и не зависит от последовательности рассмотрения записей.
В заключение еще раз хотелось бы подчеркнуть, что попытки внедрения элементов «искусственного интеллекта» в работу медицинских организаций становятся современными реалиями развития здравоохранения. И очень не хотелось бы, чтобы необдуманные спонтанные решения или не подкрепленные надежными экспериментами заявления эти процессы затормозили, отбросили, или породили мнение об их неприменимости в задачах, связанных с медициной.
Читайте по теме: Потенциал медицинских информационных систем и возможные направления оптимизации диагностических процессов
07 июня / 2019
Автор: Валерий Пулит